Data & Donuts
Open Science that’s ‘Good Enough’
2024-04-19
Today’s Presenters
Prof. Shannon Quinn
School of Computing
Prof. Kyle Johnsen
Engineering
Dr. Katherine Ireland
Research and Computational Data Management
Dr. Camila Lívio
Research and Computational Data Management
Today’s Schedule (tentative)
- 8:15: Registration ☕️ 🍩
- 8:30: Welcome & Introduction <– You are here
- 8:45: Basics of Reproducible Research (Shannon)
- 9:45: BREAK ☕️ 🍩
- 9:55: BYO Project Walkthrough (Kyle)
- 10:40: BREAK ☕️ 🍩
- 10:45: Data Management (Katherine, Camila)
- 11:20: Wrap up
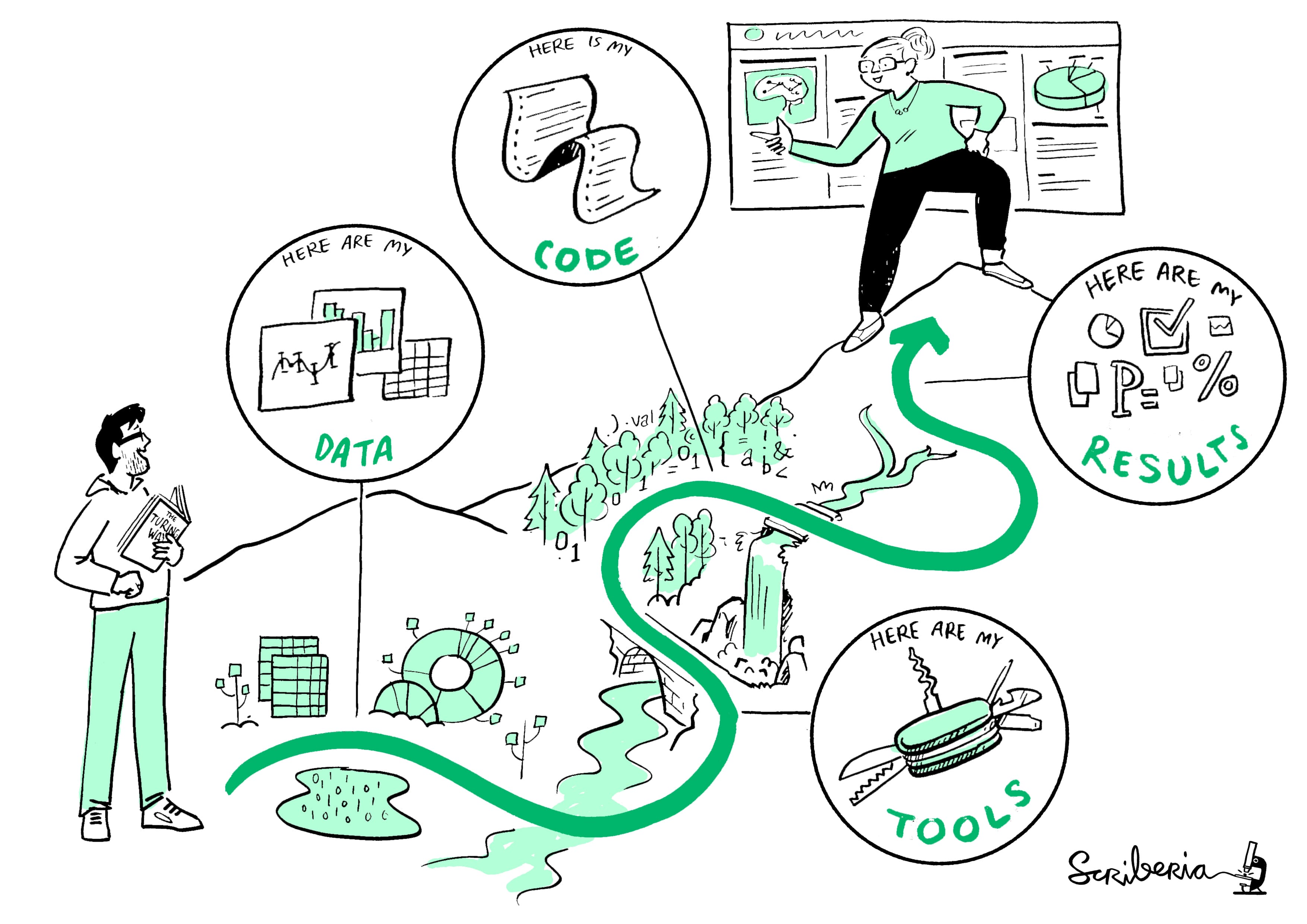
What is Open Science?
Open Science is the movement to make all scientific data, methods, and materials accessible to all levels of society.
![]()
Examples of Open Science in practice
![]()
DOI
- Open data
- Archived in a data repository (Zenodo)
- Permalinked (DOI)
- Associated metadata
- Documentation for preprocessing
- Open methods
- Proofs
- Prepackaged examples (VMs or containers)
- Serialized models (HuggingFace)
- Preregistration (OSF)
- Open access
- Preprints (arXiv)
- Open access publication venues (eLife)
- Open education
- Open Science will generate a lot of artifacts; bring those into the classroom!
- Put materials on a public-facing repo (GitHub)
- Review course materials like a manuscript (JOSE)
- The Carpentries, OSF
- Workshops just like this one
- Your university library!
Open Science is HUGE
Today, we’ll focus on a small slice:
How to get started from zero with reproducible and open research that’s good enough
(and: where to go to learn more)
![]()