Getting Started with Reproducible Research…
…that’s good enough
Goal: Make Research Reproducible
What?
The Turing Way project illustration by Scriberia. DOI .
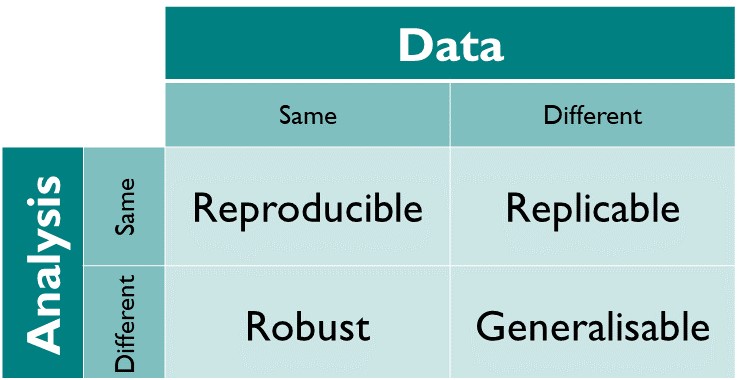
Different kinds of “reproducible”
DOI .
Today, we’re focused on “Reproducible”
We’re focused today on the reproducible dimension, but it’s good to know and understand these other dimensions, as Open Science encompasses them all.
Goal: Make Research Reproducible
Why?
Take a poll on the “why”!
Some good answers:
Scientific evidence is strengthened if it can be replicated by others (“standing on the shoulders of giants”)
Builds trust in the community
Gives researchers a “head start” on new investigations
“Negative results” can be published easily, helping others avoid time wasting pitfalls
Track a complete history of your work (“Provenance”)
Facilitate collaboration and review
Build confidence in published work
Get credit for your work
Ensure continuity
Efficiency!
Yes, efficiency! There’s admittedly a start-up cost in adopting these strategies, but time-saving across the board when we’re confident our work is reproducible.
Goal: Make Research Reproducible
How?
Goal: Make Research Reproducible
How?
Lots of ways!
Barriers to Reproducibility
If reproducibility is such a great thing to ensure in research, why are we here in 2024 learning about it (possibly for the first time)?
Again, take a poll. Some good answers:
publication bias toward novel results
too much time
requires learning new skills
no reward (e.g. job promotion)
personal: people might discover I’m wrong
Barriers to Reproducibility
If reproducibility is such a great thing to ensure in research, why are we here in 2024 learning about it (possibly for the first time)?
A slide outlining some of the barriers to reproducible research from Kirstie Whitaker’s talk about The Turing Way at csv,conf,v4 in May 2019. DOI
Reproducibility is hard
Fortunately, reproducibility is not “all-or-nothing.”
Even some reproducibility is better than none!
Today, let’s focus on “good enough”: the least amount of work to get a respectably reproducible research project.
What we’ll cover
🔁 Version control
🪪 Licensing
🌅 Environments
Versioning:
No command line git or coding; just a web interface and some filesystem munging (like creating folders)
We’ll set up a repo on GitHub and I’ll demonstrate a sample project folder structure for organizing your reproducible research project
Licensing:
I know it sounds boring but if you anticipate anyone other than yourself using, adding to, modifying, or otherwise touching your work, you need a license.
Environments:
Probably the single most difficult part of making research reproducible
A little bit about environment management
Introduction to BinderHub
🔁 Version Control
Version control is a workflow where the entire history of a set of documents is preserved.
Why do we want our work under version control?
Some good answers:
You can see everything added, removed, and changed at any point
You can review changes before they are made “official”
You can revert back to a previous version
You can restore a previous checkpoint if you lose your work
Why version control
Tracking project history. DOI .
Provenance
Version history
Hide older versions
Distributed work
Provenance is the full history of something. This can be useful for many reasons, but one is so that invariable version changes in the underlying software or its dependencies can be understood so we know how e.g. a figure was generated, by looking at the history.
Version history gives an auditable trail for why certain changes were made.
Anyone have giant commented-out blocks of code? You can delete it now, safe in the knowledge that it still exists in the history you’re recording through version control. If you need that code again, just go back to the version where it existed.
Multiple different people can work on different parts, then merge their contributions–with their own histories intact!–so you have a complete picture even as more people are contributing.
Create an account on GitHub
Create a repo
Create a repo
Fill out the form information.
Repo name : Something pithy that describes the project you’re working on.Description : A one-line summary of what you’re using this repo for.Public / Private : Suggest “public” by default, but “private” during development and “public” during and after review also makes sense.Add a README : This is where you’ll go into detail about what your repo is doing. Definitely add this!Add .gitignore : A bit more technical; depends on the work you’re doing.Choose a license : Absolutely yes–we’ll go into more detail in the next section.
Create a folder structure
This is a suggestion !
Use what is relevant, ignore what is not
(PSO: Don’t put full data in version control. Sample data is great! Or, add data/ to .gitignore)
Items like a license, README, and src are must-haves.
docs, notebooks, models, and data (for sample data, perhaps) are great-to-haves.For public-facing repos that are grown and maintained in the open, a Code of Conduct and Contributors documents are must-haves.
What else can you think of?
Add everything to version control
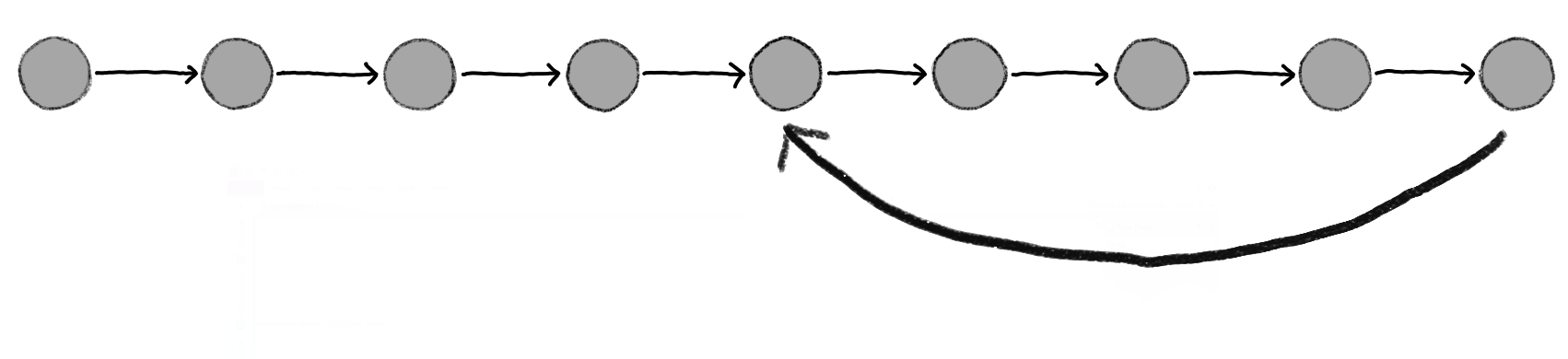
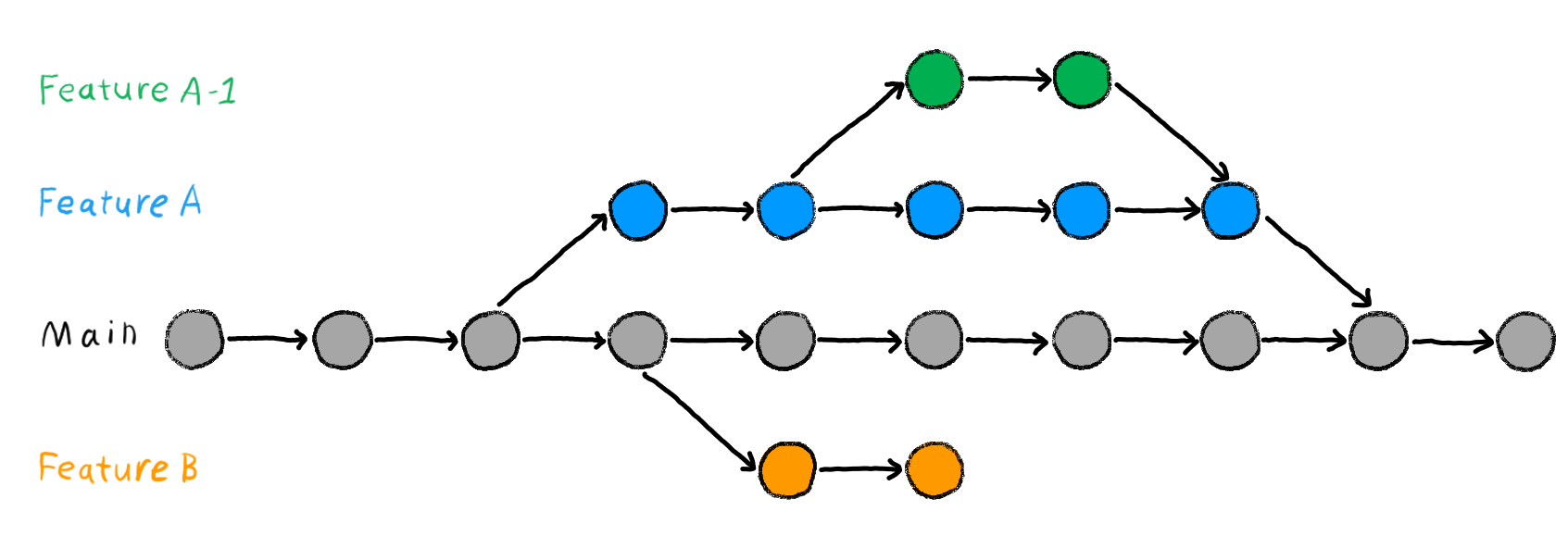
Version control workflow
I won’t go over the technical details of version control here, but suffice to say it can look like either one of these workflows. Each node is a checkpoint, and the connections between them indicate changes from that checkpoint.
Your “trees” can get quite complicated, depending on the size of the project and the number of collaborators! But it helps at least discretize the contributions, make the working spaces concrete, and prevent the buildup of FINALFINALFINAL documents being emailed.
🪪 Licensing
Licensing is how to spell out the rights of others to use, modify, or build on our work.
Why is it important to give our work (code, data, content) a license?
Some good answers:
It’s important to know how your work can be used when you put it out there
It’s important to know how you can use other people’s work in your own research
It’s VERY important to know what your rights are should someone use your work in a way you did not intend (or if someone tries to take credit for your work)
Patents, Trademarks, and Copyright
Multiple kinds of intellectual property protection.
Here, we’re focusing on Copyright .
Copyright can cover usage rights for:
Code
Data
Hardware
ML models
Content (slides, books, pictures, figures…)
Adding a license file to your repo
You can do this right when you create the repo!
🌅 Environments
Making your environment reproducible means configuring your work space–code, software, programs, even operating system–so that it is identical to the environment in which the research was originally done.
Why is it important to have reproducible environments?
Some good answers:
The same person coming back to work they’ve paused for a few months may be unable to get their code to run, as surrounding software has changed and updated in that time.
Getting a collaborator to run your code–how many times have we said “well it works on MY machine”?
If anyone wanted to replicate your results, they would need a detailed breakdown of your environment.
Debugging your code inherently relies on knowledge of what has changed and what has remained constant since the code last functioned correctly. Confidence in a replicable environment is critical for this process.
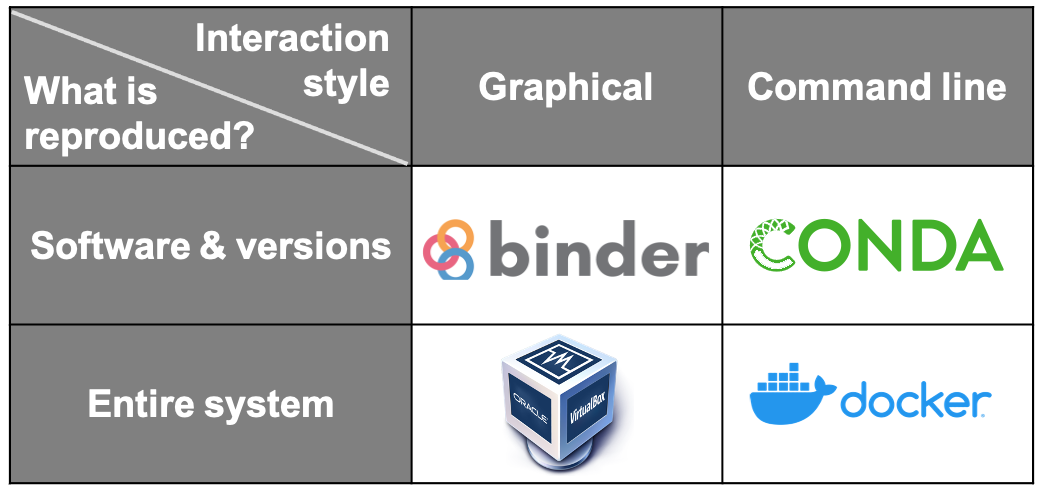
How to “capture” an environment
Computational environments. DOI .
Virtual machines
Docker / containers
Conda / Mamba
Binder
VMs are maybe the “easiest”, but certainly the most massive, ways of passing an environment around. The drawback is the size: they often clock in well into the GBs. Preferable to this would be something more akin to a recipe for building an environment locally.
This “recipe” idea is what containers aim for. Dockerfiles enumerate the “recipe” for the environment, which are excecuted locally to build it.
Where VMs and containers recreate entire compute environments, conda / mamba are package managers that are specific to coding environments (they often exist within VMs or containers). They can also specify recipes of specific coding packages and their versions that comprise a research environment.
Binder is a self-contained platform that builds a coding environment like conda/mamba but without needing the command line or a local VM or container; all you need is a repo (on GitHub) and a web browser.
Virtual machines
VirtualBox or Vagrant
Containers
Containers are often pitched as “lightweight VMs”
Build on millions of pre-built containers at DockerHub , or build your own from scratch via Dockerfiles .
“Lightweight VM” is not really technically accurate, but in practice it’s reasonable.
Pros/cons?
Has anyone ever used containers before?
Package management systems
Conda and Mamba are most well known on the Python end
Use YAML to specify the environments
Pros/cons?
Has anyone ever used conda or mamba before?
Are there other package management systems folks have used?
Binder
Converts a public repository into an active notebook environment, all via the web
Just specify the environment, and Binder does the rest!
Has anyone ever used Binder before?
Binder makes use of everything: - it’s running in cloud infrastructure (VMs) - uses your environment specification (package management, YAML) to create the environment - spins up everything inside a custom-built Docker container
One major downside: it’s very, very resource-intensive - while every effort is made to streamline image building–it watches for changes in repos, and only builds from that point–it’s a very compute intensive process - we tested a BinderHub pilot locally at UGA, and decided we just didn’t have the resources or the demand to justify it, not when mybinder.org still exists - a lot of universities ARE spinning up their own internal BinderHubs; if we need it, let us know!
So much more
Continuous integration, code testing, open access, study preregistration.
Links where you can learn more at the end of the slides.
Thank you!
Any questions?
Take this survey before leaving today!
Next up
Grab some ☕️ and 🍩
Dr. Kyle Johnsen on collaborative exercises around reproducible research practices